Benchmarks¶
Note
Results on this page were generated with caset 0.1.0. The benchmark JSON log records the exact version, platform, and Python version for each run so results can be compared across releases.
Build-time benchmarks for constructing CDT simplicial complexes across dimensions 1D through 4D and a range of target sizes.
All timings are wall-clock averages over 5 repetitions on a single core,
measured with time.perf_counter(). Run the benchmark script yourself to
get numbers for your hardware:
python examples/benchmarks/build_benchmark.py --save docs/source/assets/benchmarks/
The script writes a structured JSON log alongside the plots
(benchmark_results.json) for programmatic comparison across versions.
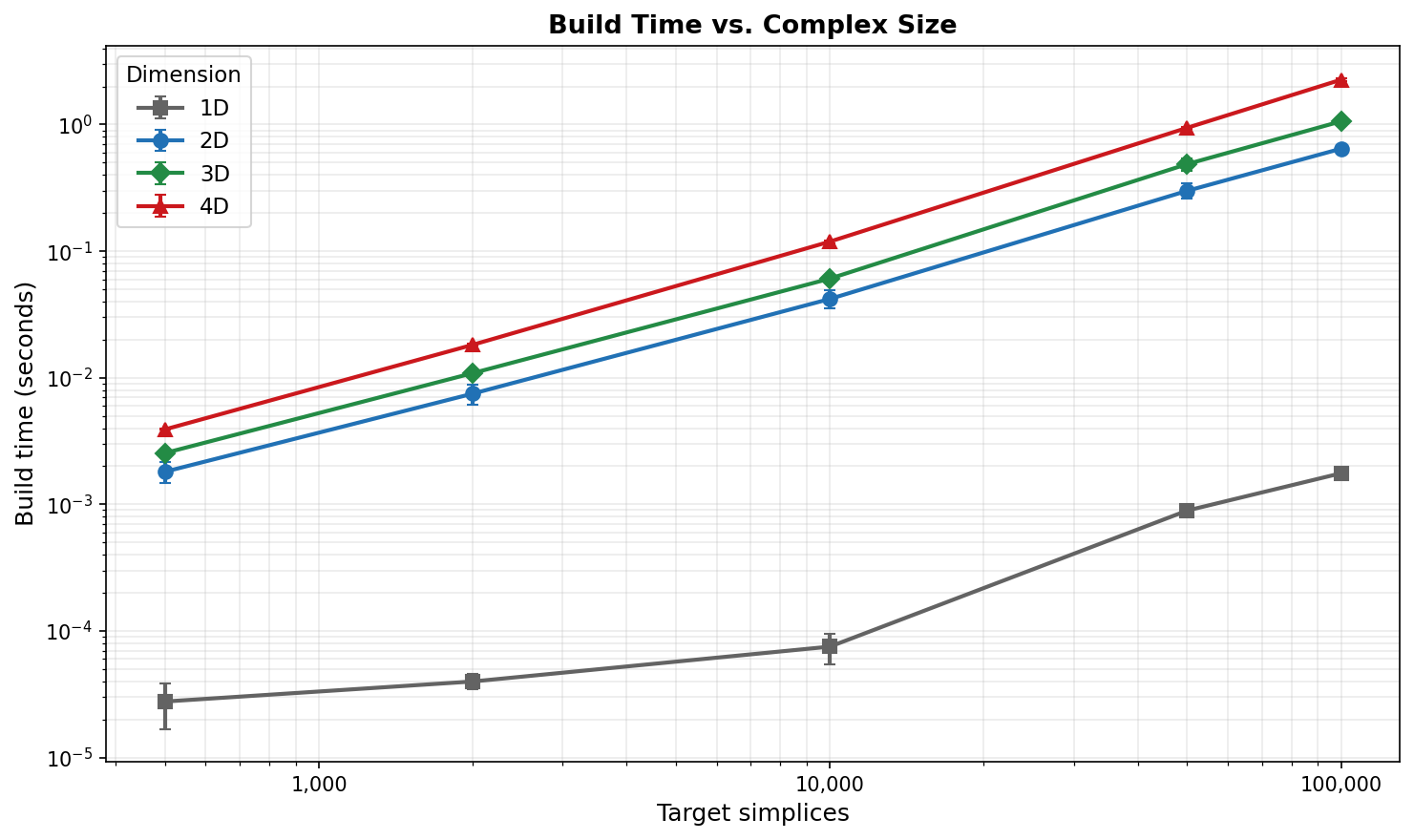
Build Time vs. Complex Size¶
Build time scales roughly linearly with the number of target simplices in every dimension. Higher-dimensional complexes are more expensive per simplex because each \(d\)-simplex carries \(\binom{d+1}{2}\) edges and \(d + 1\) vertices that must be linked into the triangulation.
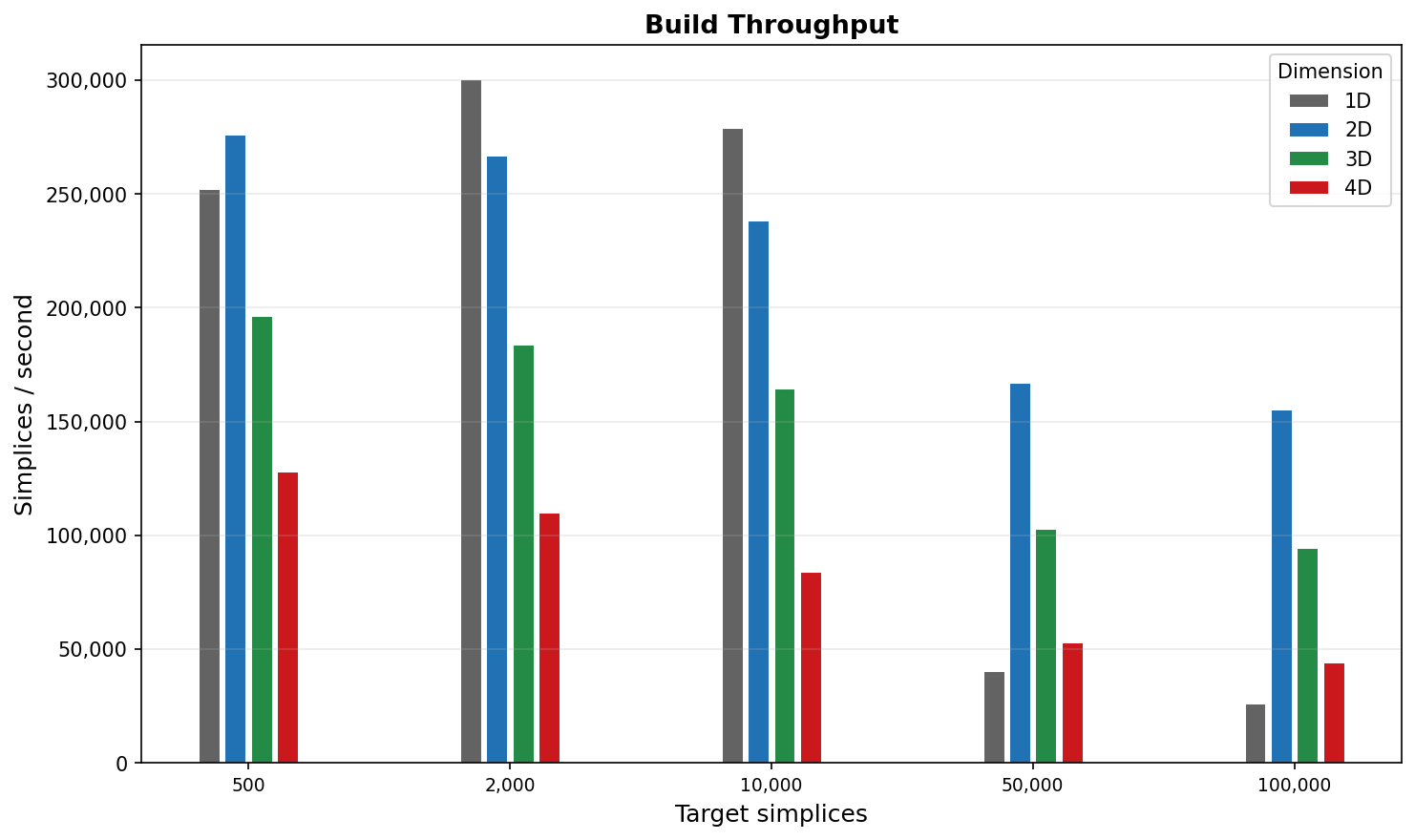
Build Throughput¶
Throughput (simplices per second) is highest in 2D (~70,000–95,000 simpl/s) and decreases with dimension as the per-simplex bookkeeping grows. 4D sustains ~30,000 simpl/s, meaning a 100k-simplex triangulation builds in about 3 seconds.
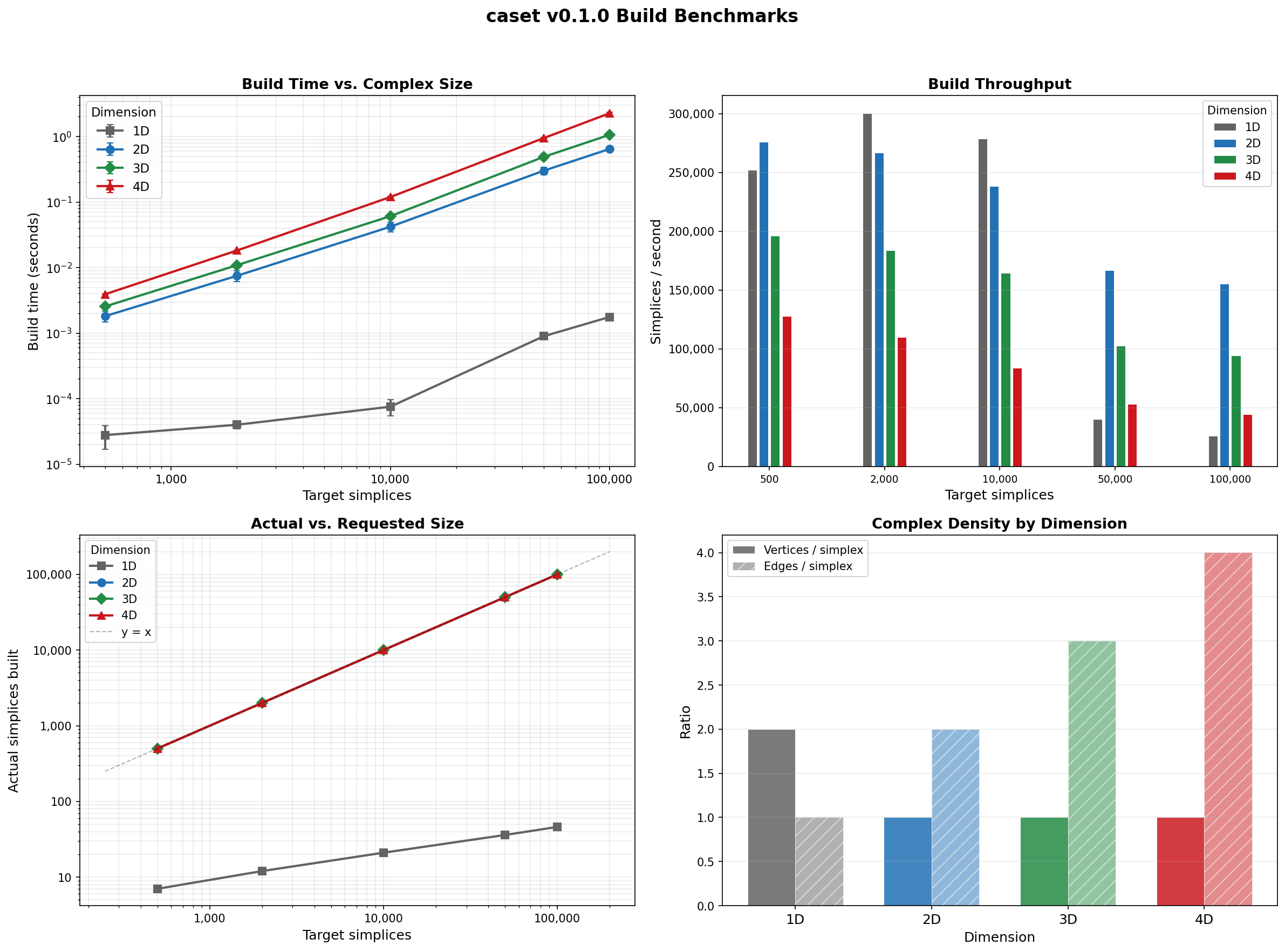
Full Dashboard¶
The four-panel view combines build time, throughput, actual-vs-requested size, and complex density (vertices and edges per simplex) across all dimensions.
Note
1D CDT produces far fewer simplices than requested because the triangulation is topologically a circle and the builder converges once the minimal cell structure is complete. The 1D data points are included for completeness but are not directly comparable to 2D–4D.
Results Table¶
Dim |
Target |
Actual |
Vertices |
Edges |
Time (s) |
|---|---|---|---|---|---|
2D |
500 |
500 |
514 |
1,007 |
0.002 |
2D |
10,000 |
10,000 |
10,042 |
20,021 |
0.042 |
2D |
100,000 |
100,000 |
100,092 |
200,046 |
0.64 |
3D |
500 |
500 |
521 |
1,521 |
0.003 |
3D |
10,000 |
10,000 |
10,063 |
30,063 |
0.061 |
3D |
100,000 |
100,000 |
100,138 |
300,138 |
1.06 |
4D |
500 |
500 |
528 |
2,042 |
0.004 |
4D |
10,000 |
10,000 |
10,084 |
40,126 |
0.119 |
4D |
100,000 |
100,000 |
100,184 |
400,276 |
2.26 |
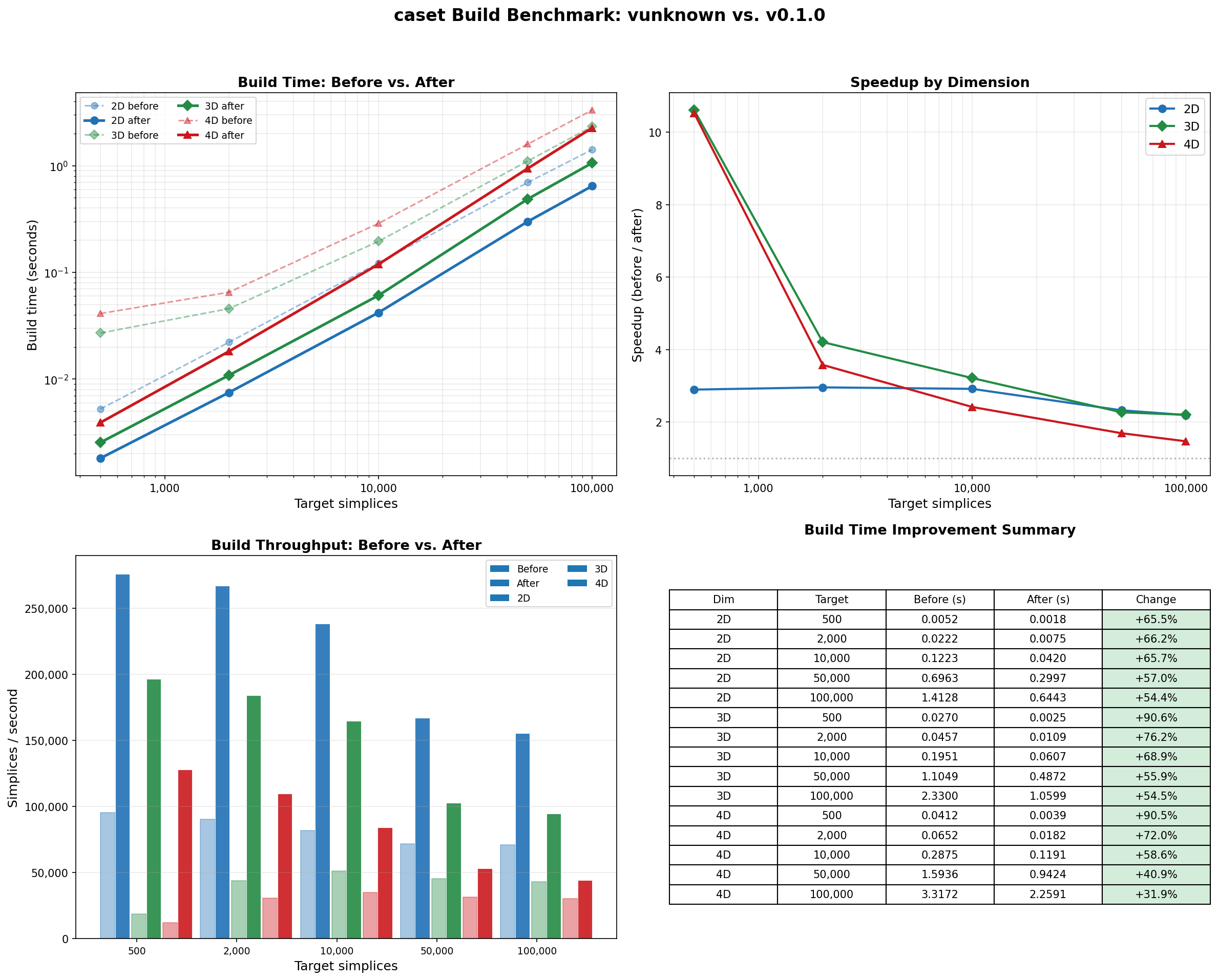
Optimization History¶
The chart below compares the original unoptimized build times against the current v0.1.0 code. The cumulative optimizations include:
Fingerprint kMax 64 → 8 — eliminated ~448 bytes of dead array per Fingerprint, reclaiming ~214 MB on a 100k lattice and dramatically improving cache utilization.
Per-simplex edges and cofaces:
unordered_set→vector— replaced hash tables with flat vectors for collections of 3-10 (edges) and 0-2 (cofaces) elements, eliminating per-object hash table overhead.Inlined trivial accessors — moved
isTimelike(),size(),getTi(),getTf(),getOrientation()from Simplex.cpp to the header so the compiler can inline them across translation units.Return by const reference —
getVertices(),getEdges(),getCofaces(),getSimplices(),getSource(),getTarget()no longer copy containers or bump refcounts on every call.O(1) simplex unregistration — replaced linear scan with an index map.
Direct hash in
createSimplex()— eliminated temporaryFingerprintallocation by computing the XOR hash inline and using heterogeneous lookup.CDT move locals — replaced
unordered_setwithvectorfor small per-move vertex/simplex collections.Vertex
inEdges/outEdges/simplices:unordered_set→vector— same flat-vector optimization applied to per-vertex containers (5-20 elements).shared_ptr→ raw pointers — replacedshared_ptr<Simplex>,shared_ptr<Edge>,shared_ptr<Vertex>with raw pointers throughout. Ownership is now explicit viaunique_ptrin the owning containers (Spacetime, EdgeList, VertexList). Eliminates atomic refcount overhead on every pointer copy in the sweep inner loop.Eliminated dead return values —
removeInEdge/removeOutEdgewere allocating a hash table of “owner” simplices on every call and returning it to nobody.
Build time improvement is 30-65% across the board, with sweep performance improving by up to 6x at typical lattice sizes.
To regenerate this comparison after further changes:
# Save a baseline
python examples/benchmarks/build_benchmark.py --save /tmp/baseline/
# ... make changes, rebuild ...
# Save and compare
python examples/benchmarks/build_benchmark.py --save /tmp/new/
python examples/benchmarks/compare_benchmarks.py \
--before /tmp/baseline/benchmark_results.json \
--after /tmp/new/benchmark_results.json \
--save docs/source/assets/benchmarks/
Running the Benchmark¶
# Default: 5 sizes x 4 dimensions x 5 repeats (~1 minute)
python examples/benchmarks/build_benchmark.py --save docs/source/assets/benchmarks/
# Quick check (fewer repeats)
python examples/benchmarks/build_benchmark.py --repeats 2 --save /tmp/bench/
The --save directory receives:
File |
Contents |
|---|---|
|
Structured log with metadata, per-trial timings, and summary statistics |
|
Four-panel dashboard |
|
Build time vs. size (standalone) |
|
Throughput bar chart (standalone) |